On the Subtleties of Software Optimization Evals
Software optimization benchmarks are becoming a key axis for tracking AI R&D progress: they ask not “did it work,” but “how much faster/cheaper did it get,” and the hard part is aggregating that across diverse tasks without measuring the wrong thing.
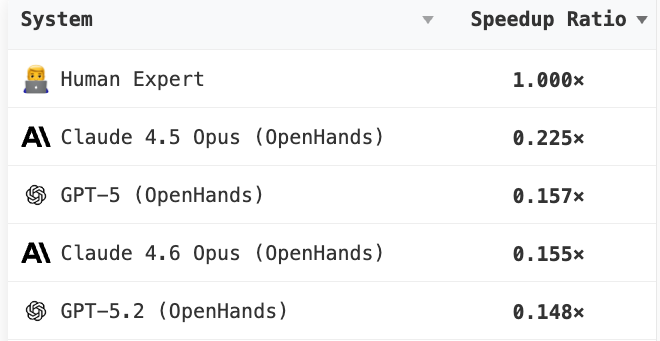
I’ve been thinking about this since creating the GSO benchmark, but have been excited to see other great evals pop up in this space: AlgoTune, KernelBench, SWE-fficiency, etc. But SWE-fficiency’s latest leaderboard seemed ~unintuitive: Opus-4.5 > GPT-5 > Opus-4.6 > GPT-5.2 … which got me to unpack some unobvious challenges in optimization evals:
Setup Overview
SWE-fficiency evaluates models on 498 tasks to optimize codebases (pandas, numpy, scipy, etc.) in a reasonable setup. For each task, a human expert wrote a performance-improving PR. Models are scored on their Speedup Ratio (SR): how much of the human’s speedup did they achieve?
\[\text{SR} = \frac{\text{model_speedup}}{\text{gold_speedup}}\]Crucially, if a model’s patch fails any correctness test, it gets no credit and SR is set to $1 / \text{gold_speedup}$ for that task. SRs are then aggregated across tasks via harmonic mean (HM).
Challenges with Aggregating Speedup
Digging into transcripts and logs, the rankings come down to how the aggregate metric handles incorrectness + headroom:
1. One task can dominate HM
The issue isn’t HM per se — it’s standard. The concern is interpretability when aggregating across heterogeneous tasks: with gold_speedup spanning an extreme range (1.01×–50,872× in this benchmark), SR becomes very sensitive to outliers, and HM makes near-zero SRs disproportionately influential.
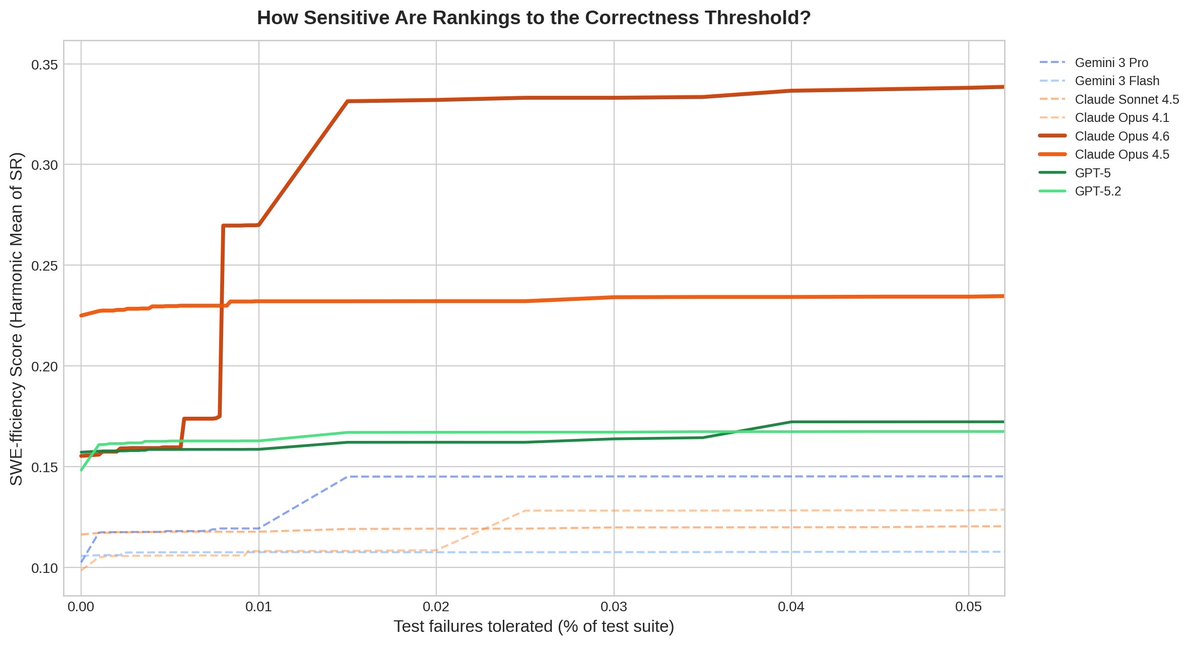
One task (pandas-dev__pandas-29134) has a gold speedup of 50,872×. Opus 4.6 produced a fast optimization but left a few debug print()s that tripped 3 tests out of 38,117 (99.99% pass rate). Under the current rules this is fully incorrect, so SR collapses to ~0.00002. A single high-headroom near-miss like this can dominate the aggregate and obscure the apples-to-apples comparison you care about.
2. Correctness penalties are implicitly headroom-weighted
By definition, the penalty for being “incorrect” isn’t just binary, it scales with gold_speedup. A fail on a high-headroom task is treated as orders of magnitude worse than a fail on a low-headroom task — even though in practice both patches would simply be reverted. Failing a handful of tests on a 1.05× gold task barely matters; failing a handful on a 50,000× gold task is catastrophic. That’s a reasonable design choice if you want “headroom-weighted correctness,” but it’s not obviously the same as “strict correctness.” This implicit coupling can flip rankings.
Taking Stock. Binary correctness is reasonable; shipping wrong code is wrong. The subtle issue is the mapping from “incorrect” → SR = $1/\text{gold_speedup}$, combined with an aggregation that amplifies tiny SRs.
In practice, many “incorrect” instances are near-misses (61–86% pass >99% of tests). So minor mistakes (failing <0.05% of tests) on a few high-headroom tasks can swing the leaderboard, as seen below:
Takeaways
This isn’t an argument to “soften correctness,” nor a critique of any single eval: open-ended speedup across tasks is still the most intuitive target. The point is that small metric choices can create brittle aggregates and misleading capability conclusions.
To be honest, I ran into similar (extremely) hard challenges with GSO and ultimately chose the easy way out: a thresholded binary metric (did the model achieve ≥95% of the human’s speedup?). I don’t think that’s ideal either; it reduces signal and limits runway, but it controlled brittleness.
As optimization capabilities become more important in 2026, it’ll be crucial to understand all sources of FUD beyond the usual measurement noise, including something as simple as metric design.